· Cloud Development · 15 min read
3 Survival Patterns for Navigating CAP Schema Changes
In CAP, removing a field from your model removes it from the DB. Yes, even in production. If that makes you uncomfortable, good. These 3 patterns bring safety back to CAP development.

TL;DR / What You’ll Learn
CAP gives you speed early because your CDS model is the source of truth, and everything just works. But when your app developments go into different teams, across landscapes, and get deployed with a CTMS transport, that speed turns brittle fast. Git doesn’t protect you. Your schema can drift, be overwriten, or disappear in silence along with the data. This guide lays out three survival patterns to bring clarity, safety, and control back into the picture.
The Trade-off: Speed vs. Reliability in CAP Schema Changes
Early CAP development feels fast. You define your Core Data Services (CDS) model and run against an in-memory setup, SQLite, H2, or a local SAP HANA Cloud instance, and iterate freely. Ephemeral setups reset with every restart. File-based and HANA Cloud setups persist between runs and require resets when they drift. Testing is responsive. Schema resets are quick. Developers can focus entirely on application logic. This speed is a feature, not a flaw.
But that same model-first approach, when pushed toward shared or production landscapes, creates fragility. In CAP, the CDS model defines the source of truth for your database. When the model changes, those changes are reflected in the schema. There is no version history and no default process for preserving or reconciling what is lost along the way.
As teams grow and environments multiply, coordination gets harder. Shared development environments use SAP HANA Cloud and the HANA Deployment Infrastructure, or HDI, to apply changes. HDI aligns the live schema with the current CDS model by comparing generated artifacts and applying only deltas. There is no built-in safeguard for timing mismatches or accidental deletions. If someone removes an entity or field from the model and deploys without coordination, those definitions can vanish. This often goes unnoticed until something breaks. Fixing it is slow. Recovery usually involves backups, diffing commits, or manually rebuilding artifacts. It costs more than the original change or, worse, erodes business confidence when systems behave unpredictably. These issues are often not prioritized if they are not in production. The risk accumulates quietly. The longer they linger, driven by technical inertia or atrophy, the more expensive, disruptive, and politically charged the recovery becomes. At that point, it is the business’s development, not the engineers’.
Things get even more disconnected when deployments are routed through SAP’s Cloud Transport Management Service, or CTMS. CTMS transports Multi-Target Application Archives, which are bundled packages of application code, configuration, and schema artifacts. These deployments are sequenced based on business needs, not commit history. A last-minute emergency break fix can override an earlier MTAR built from multiple approved change requests. Once deployed, there is no link between what was committed and what now runs.
In that workflow, Git offers version control but not process control. The model is all or nothing. MTARs are all or nothing. CTMS operates on its own calendar. Developers treat Git like production, but CTMS does not. Unless teams build traceability into their workflow, what goes live is determined more by transport sequencing than by engineering intent.
Survival Pattern 1: Expand and Contract Schema Changes for Safe Rollouts
Most CAP developers start by treating schema changes like code. Make the update, deploy it, and move on. But that assumes everyone is updating together. In reality, they’re not. Teams work on different timelines. Features are gated by approval. Environments move at different speeds.
When schema changes are tied directly to application logic, deployments break easily. This pattern adds structure. It separates database changes from feature delivery. You can ship schema updates early, migrate data safely, and switch logic on only when everything is ready whether that’s through feature flags, staged rollout, or coordinated deployment.
It’s the foundation for Zero Downtime Deployment (ZDD) of the app and Zero Downtime Maintenance (ZDM) of the schema. More importantly, it restores control. You move forward in small steps, at your own pace, without risking what’s already working.
Example: Replacing isPublished Boolean with a status Enum in a BlogPost
Suppose you have a blog platform with a simple boolean field isPublished that indicates whether a post is published or not. You want to replace this with a new status field, which is an enumeration that supports multiple states like `Draft, InReview, and Published.
Step 1: Expand - Add the New Field
Add the new status field while keeping the existing isPublished field:
type Status : String enum {
Draft;
InReview;
Published
} default 'Draft'
entity BlogPosts cuid, managed {
content : String;
isPublished : Boolean default false;
status : Status; // New field for phased migration
}Deploy this change. The database now has both fields. Your application can write to both or either field during this phase.
Step 2: Backfill - Migrate Existing Data
Run a separate data migration script to populate status based on the value of isPublished:
UPDATE BlogPosts
SET status = CASE WHEN isPublished = true THEN 'Published' ELSE 'Draft' END
WHERE status IS NULL;This script is idempotent, meaning it can be run multiple times without causing errors or duplicate changes. It only updates rows where status is NULL.
How you run this migration depends on your deployment and operations process. The key requirement is that the data is safely backfilled before the application fully transitions to the new schema. Choose the method that best fits your environment and governance needs.
Step 3: Migrate - Update Application to Use status
Update your application code to use the new status field while still supporting fallback to the old isPublished during transition:
entity BlogPosts as projection on BlogPosts {
*,
case
when status is not null
then status
when isPublished
then 'Published'
else 'Draft'
end as status
}Deploy this update. Your app now uses the newstatusfield when possible but falls back gracefully if status is not yet populated.
Step 4: Contract - Remove the Old Field
Once the application is fully switched to status, and no code depends on isPublished, remove the old field:
entity BlogPosts cuid, managed {
content : String;
status : Status;
}You can now safely remove the legacy field.
Why This Pattern Matters
- Keeps your schema and application backward compatible at every stage.
- Reduces the risk of deployment failures and downtime.
- Separates concerns: database changes, data migration, and application updates are handled independently.
- Allows safe, phased rollouts especially in high-availability environments.
- Defers cleanup of old schema until it is safe to remove.
- Idempotent migrations improve safety by allowing retries and repeated runs without side effects.
- Traceable, incremental changes are easier to review, test, and revert than large batch updates.
This pattern solves for safe evolution, but without visibility, even safe steps can collide. The next pattern adds traceability.
Survival Pattern 2: Track Schema Evolution Safely with @cds.persistence.journal
In non-CAP environments, like Postgres with Liquibase, schema changes are typically managed through versioned migration scripts. CAP supports this model too (see guide). However, the typical CAP use case targets SAP HANA, where schema evolution can be tracked using @cds.persistence.journal.
This annotation enables automatic generation of HANA migration tables (.hdbmigrationtable files), capturing incremental schema changes. For details, see Enabling.hdbmigrationtablegeneration and SAP Help: Migration Tables (.hdbmigrationtable).
Starting with a Simple Addresses Entity
Let’s walk through a scenario using a customer address.
We first add the annotation and define the entity:
namespace sap.capire.incidents;
@cds.persistence.journal
entity Addresses : cuid, managed {
customer : Association to Customers;
city : String;
postCode : String;
streetAddress : String;
}We then build using:
cds build --for hanaAt this point, CAP generates the migration artifacts needed to track schema evolution. You will see .hdbmigrationtable files (for example, Addresses.hdbmigrationtable) reflecting the current schema version 1. 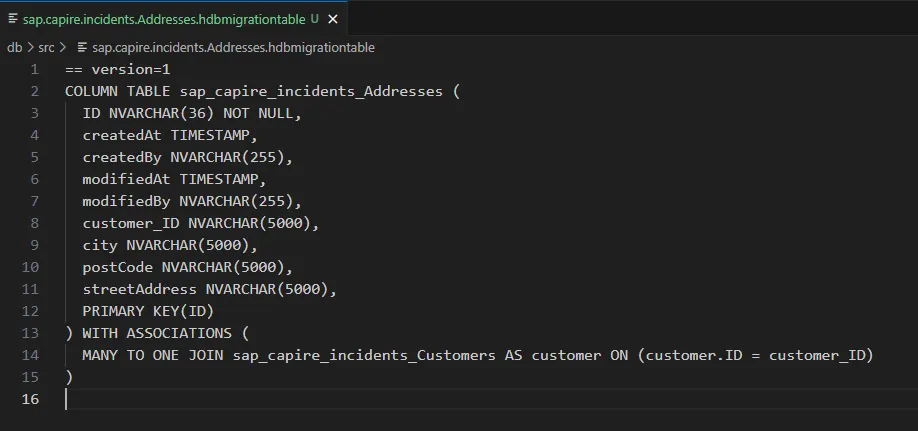 this is your baseline. Every model change from here on becomes auditable.
this is your baseline. Every model change from here on becomes auditable.
 Your Git changes will include important files such as:
Your Git changes will include important files such as:
schema.cds- your updated CDS modelcsn.json- the baseline compiled model stored indb/last-dev/- The new migration files These are now staged and ready for commit. The
csn.jsonfile serves as the baseline snapshot of your production schema, which CAP will use to compare against future changes.
Adding New Fields -state and country as Strings
Next, we update the Addressesentity to include two new missing fields state and country both as strings:
namespace sap.capire.incidents;
@cds.persistence.journal
entity Addresses : cuid, managed {
customer : Association to Customers;
city : String;
postCode : String;
streetAddress : String;
state : String; // New field - added in version 2
country : String; // New field - added in version 2
}After building the changes:
cds build --for hanaCAP generates migration files reflecting the schema changes. 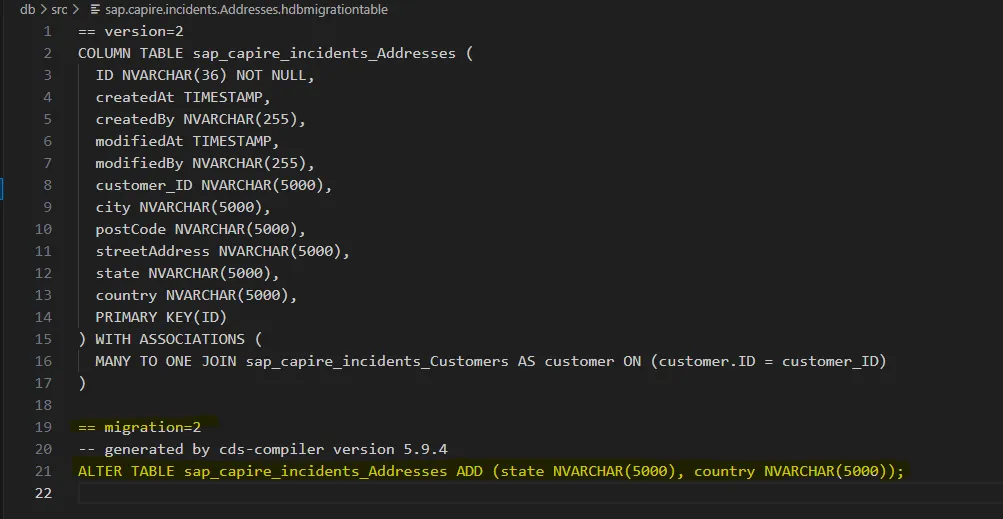 Version 2: Additive Change
Version 2: Additive Change state and countryadded via ALTER TABLE. First time seeing raw SQL? Good. Commit it. This is traceability in action.
Changing country to a Standard Association for Usability and Reporting
To improve usability and reporting, we change country from a free-text string to an association. This allows users to choose from a predefined list via a dropdown instead of entering arbitrary text. It also standardizes the data, making reporting more accurate and consistent.
Here’s how the updated Addressesentity looks using the standard country association from the common package:
using { cuid, managed, Country } from '@sap/cds/common';
namespace sap.capire.incidents;
@cds.persistence.journal
entity Addresses : cuid, managed {
customer : Association to Customers;
city : String;
postCode : String;
streetAddress : String;
state : String;
country : Country default 'AU'; // New type - added in version 3
}After building the changes for the new country_code column and association, the Addresses.hdbmigrationtable file updates to version 3. 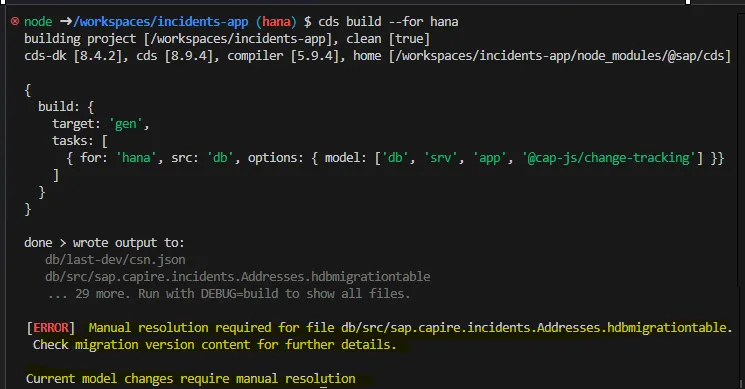
The build fails with an ERROR highlighting manual resolution required, the migration file says why DROP statements cause loss of data.
>>>>> Manual resolution required - DROP statements causing data loss are disabled by default.
>>>>> You may either:
>>>>> uncomment statements to allow incompatible changes, or
>>>>> refactor statements, e.g. replace DROP/ADD by single RENAME statement
>>>>> After manual resolution delete all lines starting with >>>>>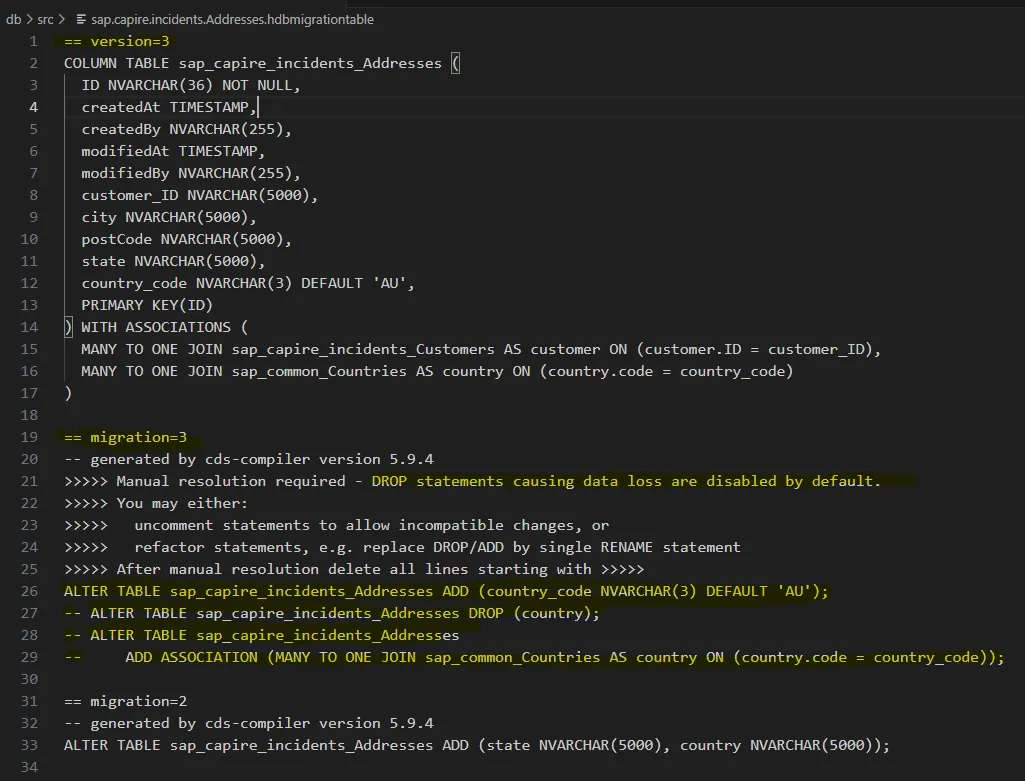 Version 3: Breaking Change (Manual Resolution Required) We’ve replaced
Version 3: Breaking Change (Manual Resolution Required) We’ve replaced country : String with country : Country default 'AU', a semantic improvement, but a technical risk. CAP generates:
- a new
country_codecolumn - a commented-out
DROP COLUMN country - a build-time warning flagging manual resolution required
Why? Because dropping country would lose existing data. Before uncommenting that line:
- Migrate old
countryvalues intocountry_code - Ensure they align with codes in the
Countrytable - Only then is it safe to drop the original column This is where traceability meets responsibility. The tool won’t stop you, but it will warn you.
Why Manual Intervention is Needed
This warning shows that manual intervention is required before deploying the schema change. Migrating from free-text country names to standardized country codes isn’t automatic, entries like "United States", "USA", and "America" all need to map to a single code like "USA" to avoid data loss.
What Happens If You Don’t Use Schema Evolution
Deploying schema changes without migration scripts can cause deployment errors, silent breakages, or untracked data loss. CAP will rebuild your schema from the model and treat removed fields like they never existed. That works in dev, but in production, it’s dangerous.
Using @cds.persistence.journal and its .hdbmigrationtable files gives you a safe path forward, additive changes are handled automatically, risky ones are flagged, and every schema update becomes a visible, versioned artifact.
This Only Works If You Commit to It
Migration files only help if someone remembers to commit them. Miss a commit, skip a review, and the next deploy might quietly drop a column no one meant to lose. CAP won’t warn you, because the tooling’s there. Traceability helps you see it. Pattern 3 is what catches it before it lands.
Survival Pattern 3: Enforce Governance with a Migration Check
In a CAP application that’s already in production, persistence model changes must be coordinated across teams. When developers introduce changes locally without alignment, those updates may go unnoticed or unreviewed. This lack of visibility can lead to schema inconsistencies between environments, overwritten definitions, unclear ownership of changes, and failures in features that were previously working. These issues often only appear during or after deployment, when it’s harder to react quickly or trace the root cause.
Migration checks help address this by validating changes against the known production schema before deployment. If a change is unapproved or unexpected, the check can block it, freeze key structures, or require explicit admin review. This helps teams ensure that every schema change is intentional, reviewed, and consistent across all environments.
It wasn’t always obvious this tool existed. Tucked away in
@cap-js-community/common, Migration Check shipped quietly, no headlines, no fuss. But it solved a problem before most teams had named it. Hats off to the AFC team. This is one of the most thoughtful governance layers in CAP today.
You’ll find it here on The Migration Check – GitHub
The next section shows how to wire it up and use it in practice. You can freeze parts of the schema, block risky edits, or require admin approval - a guardrail, not just a warning.
Approve Before You Break: Schema Change Workflow
Note: These steps show the process, but in most real projects, they’re wired into your mta.yaml build or run automatically before peer review. The goal is to make sure schema checks happen before deploys, not after incidents.
One-Time Setup (Project Lead)
As the project lead or architect, you’re not just setting up tools, you’re setting expectations. These steps define how schema changes are tracked, approved, and enforced across the team. Once this is in place, Git becomes more than version control. It becomes schema governance.
- Install the CLI:
npm install --save-dev @cap-js-community/common- Configure migration check in your project
{
"cds": {
"migrationCheck": {
"whitelist": true,
"keep": false
}
}
}- (Optional) Add reusable scripts to your
package.json:
"scripts": {
"cds:build": "cds build --production",
"cdsmc": "cdsmc",
"cdsmc:update": "cdsmc -u",
"cdsmc:admin": "cdsmc --admin"
}- Build for production:
npm run cds:build- Seed the production baseline:
npm run cdsmc:updateFiles Created or Changed
After setup, you will see:
package.json
migration-check/csn-prod-hash.json
migration-check/csn-prod.json
migration-check/migration-extension-whitelist-hash.json
migration-check/migration-extension-whitelist.jsonYou’re the lead. Own the baseline. These files aren’t just outputs, they’re the contract. If it’s not in Git, it doesn’t count.
Developer Flow: Submit a Change for Approval
Example: Adding a Field to the Model
entity Customers : managed {
key ID : String;
firstName : String;
lastName : String;
name : String = firstName ||' '|| lastName;
email : EMailAddress;
phone : PhoneNumber;
creditCardNo : String(16) @assert.format: '^[1-9]\d{15}$';
dateOfBirth : Date; // <-- new field added
..
}Steps:
- Make your change in the CDS model (as shown above).
- Build and run migration check:
npm run cds:build
npm run cdsmc- If you see an error (e.g.,
NewEntityElementIsNotWhitelisted), you will see output similar to the screenshot below: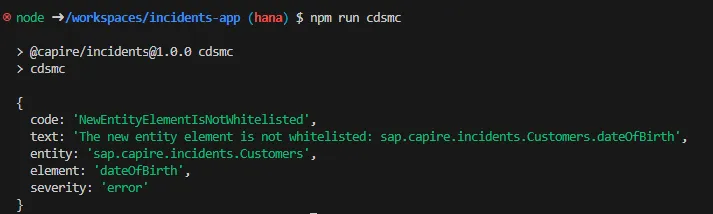
- Notify the Project Lead or Approver.
- Wait for approval before proceeding.
Admin Instructions: Approving a Model Change
When a developer’s change is blocked by the migration check, you have two options:
Option 1: Whitelisting the Field
- The developer proposes a change and explains the intent.
- The change is reviewed.
- The admin updates the whitelist file:
{
"definitions": {
"sap.capire.incidents.Customers": {
"elements": {
"dateOfBirth": {}
}
}
}
}- The admin pushes the change to git.
- The admin communicates back to the developer that it is done.
Use this path for routine changes like non-breaking field additions that meet project norms. It keeps things lightweight while still enforcing a second set of eyes.
Option 2: Approve with One-Time Hash
Use this when a change isn’t yet whitelisted, but the admin agrees it’s safe to proceed - just once.
- The developer proposes a change A new field is added to the model and the intent is explained to the admin.
- The change is reviewed The admin assesses risk and decides it’s acceptable without updating the whitelist.
- The admin runs the approval check
npm run cdsmc:admin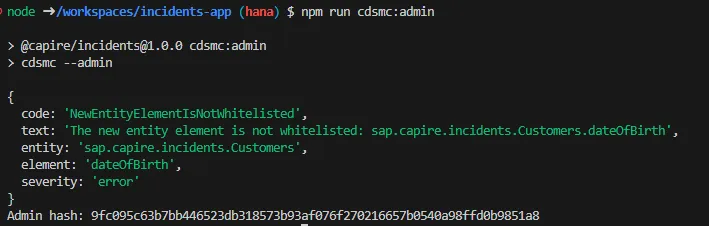 This lists all schema violations and generates an
This lists all schema violations and generates an adminHash for approval:
{
code: "NewEntityElementIsNotWhitelisted",
...
adminHash: "04b4eb624d47dcae08cbe1423c33581dee53..."
}- The admin adds the hash to
package.json
"cds": {
"migrationCheck": {
"whitelist": true,
"keep": false,
"adminHash": "04b4eb624d47dcae08cbe1423c33581dee53.."
}
}- The admin commits and pushes the change to Git This signals the override is authorized, visible and auditable.
- The developer reruns the migration check again:
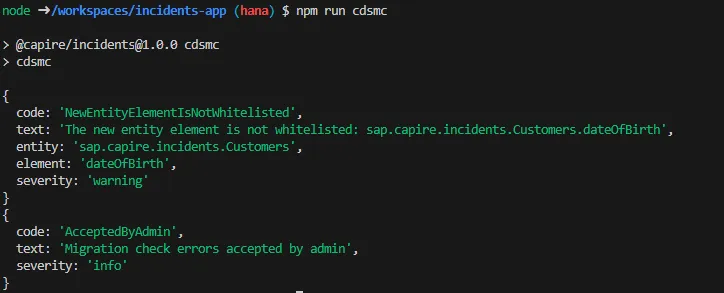 The error is now marked as accepted:
The error is now marked as accepted:
{
"code": "AcceptedByAdmin",
"text": "Migration check errors accepted by admin"
}- Pipeline or Admin reseeds the production baseline
npm run cdsmc:updateThis updates the production baseline to match the new schema.
- Admin removes the one-time override After confirming the schema is deployed and the new baseline is committed, remove the
adminHashfrompackage.jsonand push the cleanup.
One-time override. Shared responsibility. The adminHash approves a schema change once, without whitelisting. Auditable, short-lived, versioned via package.json. Not ideal, but it is open source. Patterns can grow.
What You Should Walk Away With
- CAP is built for speed, especially at the start. But once your project crosses into production, raw speed matters less than control and confidence.
- The CDS model is the system’s source of truth. Removing a field from the model removes it from the schema, even if data is still in use.
- Git alone is not enough. Developers will push changes directly to DEV and QA to test. Without checks, things drift long before they reach review.
- When your transport process is governed by CTMS, Git no longer dictates deployment order. That means your process, not your repo, must enforce consistency.
The three survival patterns help you regain that control.
- Expand and Contract makes schema changes safer and backwards-compatible.
- Schema Journaling tracks incremental changes and surfaces risk.
- Migration Check puts guardrails on what gets through.
You can start with any one of these. Used together, they provide a complete safety net supporting fast iteration without sacrificing traceability, auditability, or operational stability.
It’s not about slowing down. It’s about making sure what moves fast doesn’t get lost on the way. Tooling can scaffold structure. Only people prevent damage.
About the Author
John Patterson is a Principal Software Engineer at Second Phase Solutions. After 25 years of schema scuffles and deployment déjà vu, he treats governance less like process and more like pest control. Always collecting war stories. Connect on LinkedIn.